AxeDB: Guitar Pricing Intelligence
New project for studying the used and vintage guitar markets
November 01, 2016
Literature is a tricky area for data science. Think of your five favorite books. What do they have in common? Some may share an author or genre, but besides that, it is probably hard for you to think of what traits they share. Drew Hoo, Aniket Saoji and I set out to explore the mysterious components of an individual’s literary taste profile, and in the process built a content-based recommender system for books. In this post I will give a brief overview of the system, the features it uses, and how it was built. For a deeper dive into the nuts and bolts of the system, see the github repo here.
The first challenge was finding data. People’s literary tastes span an incredibly wide range of topics and styles; to effectively model these we need a large amount of data on each of these categories. For this reason, our approach was to get as much data as possible. We pulled the text file for every book, magazine, almanac, and so-on from the world’s largest Internet library, Project Gutenberg. The data set totaled 55,000 texts, which amounted to approximately 22gb of raw text.
With the data obtained, we then had to do something with it. Raw text is unstructured data, so in order to perform any useful analyses or recommendations, we first have to extract features from the text. To begin with the low-hanging fruit, we first extract the title and author of the text, since these are conveniently placed in the header of each Project Gutenberg text file with consistent, easy to parse formatting. From here, however, it gets more interesting.
We were next inspired by this post from Adam J Calhoun, visualizing different authors’ punctuation profiles. A punctuation profile includes the relative frequency of each punctuation mark’s use, compared to the text’s punctuation count as a whole. Extracting this profile from each text, we found common patterns that proved useful in understanding links between texts. Theatrical texts, for example, had high scores for semicolon use, due to their common structure of beginning each line with
CHARACTER NAME: (the character’s line)
Similarly, poetry scored particularly low for period usage, and mathematical texts scored high for exclamation point and plus sign usage, due to their usage in mathematical notation. These results show that punctuation profiles help to understand not only literary style, but also basic structural and categorical features of a text. An example of punctuation profiles, from Calhoun’s analysis, is shown below.

Moving past punctuation profiles, we then explored part-of-speech profiles, examining authors’ relative use of verbs, adjectives, pronouns, and other parts of speech. These results were similarly useful in identifying patterns between works. A few patterns we found were that novels tended to rely heavily on verbs in order to share plot points, where scientific texts tended to be rely heavily in adjective use in order to describe their discoveries.
Our next set of features were sentiment scores. An important feature in someone’s literary tastes is whether they enjoy books that are generally positive, negative, or neutral in sentiment. We used Natural Language Toolkit’s VADER sentiment analyzer in order to extract this information. VADER proved preferable to the more commonly used Naive Bayes approach because it takes lexical and rule-based patterns into account such as capitalization and punctuation patterns, which help to catch difficult-to-identify features such as sarcasm and emotion. “STOP!,” for example, has stronger emotional value attached than “stop.,” and this type of difference is captured particularly well by VADER.
In general there was very little variance between texts in terms of their positive and negative sentiment scores. The most useful result of using sentiment analysis, contrary to expectations, was that it did an excellent job of identifying academic texts. The highest scoring texts in the “neutral” sentiment feature included Darwin’s Coral Reefs, various biology and chemistry textbooks, history books, and various obscure almanacs and fact books.
The final and most important feature we extracted was each book’s content classification. The general strategy for obtaining this was to use three layers of clustering: one high-level cluster, for capturing genre-level similarity, one intermediate-level cluster, for capturing the topic of the text, and one highly specific cluster, for capturing niche categories and sub-categories of content. We do this using k-means clustering on each book’s TF-IDF scores, using three different values for the number of clusters.
A TF-IDF score is a word’s term frequency times its inverse document frequency. In short, this represents how important a word is to the book it belongs to, relative to how common it is in the broader world of literature. The insight of this score is that if a word is used heavily in one text, and rarely in the rest of literature, then that word is a distinguising feature for that particular text. More explicitly,
\[{tfidf} (t,d,D)={tf} (t,d)\cdot{idf} (t,D)\]where
\[{tf} (t,d)= f_{t,d}\]and
\[{idf}(t, D) = \log \frac{N}{\vert\{d \in D: t \in d\}\vert}\]Where $f_{t,d}$ is the frequency of term $t$ in document $d$, $N$ is the number of documents in the corpus, and the term in the denominator of ${idf}$ is the number of documents in which term $t$ occurs.
Calculating these scores for all 55,000 of Project Gutenberg’s e-books was computationally challenging, requiring massive matrix multiplications due to the large number of both terms and documents in this corpus. This computation was made possible, however by distributing the job across multiple nodes using Apache Spark on Amazon Web Services’ Elastic Mapreduce platform.
Using these TF-IDF scores, we then used k-means to identify clusters of similar books. K-means is a simple clustering algorithm that assigns data points to clusters based on their proximity to a cluster centroid, which is a point at the center of the cluster. The algorithm iteratively updates centroid locations and re-assigns data points to their new clusters until the cluster memberships stabilize, thus finding the best clustering results for that set of centroids. With each book’s array of TF-IDF scores as our data points, we ran k-means clustering for a small, medium, and large number of clusters, capturing general, intermediate, and granular degrees of similarity between the books’ vocabularies.
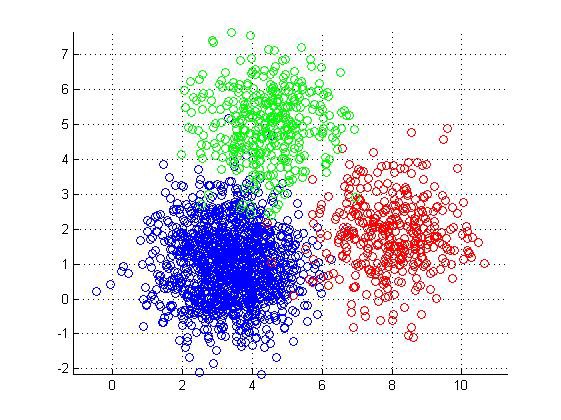
K-Means visualization in 2 Dimensions
The clustering results were by far the most useful for making recommendations, accurately identifying books that were similar in content. Some examples of what the three levels of clustering found are shown in the tables below.
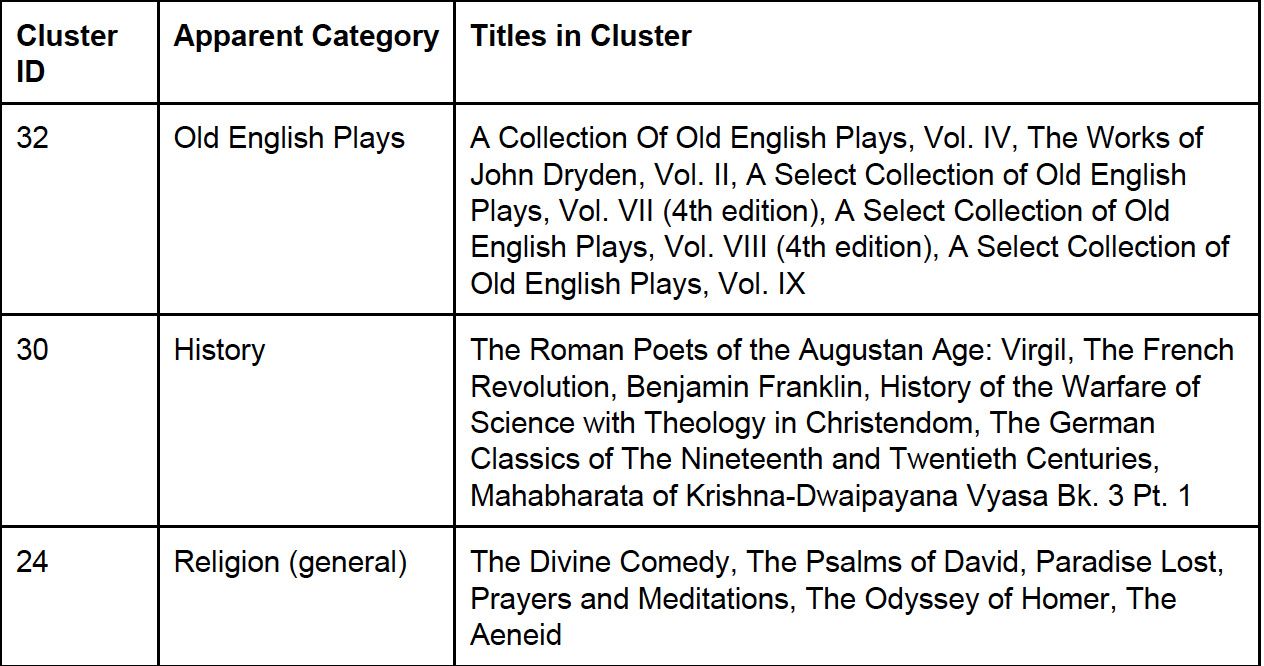
Intermediate-Level Clusters: K = 50
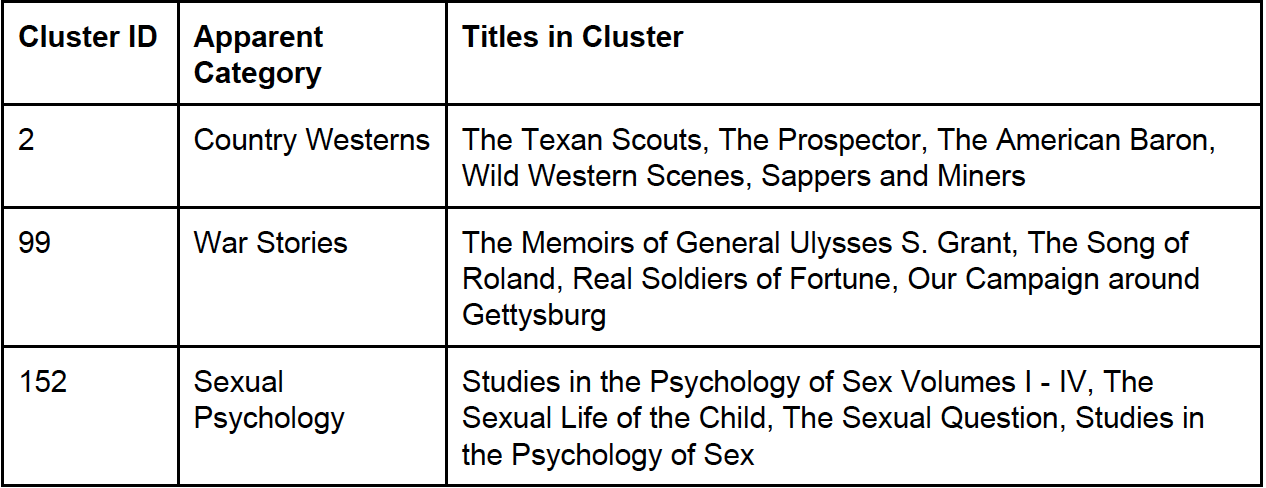
Intermediate-Level Clusters: K = 155
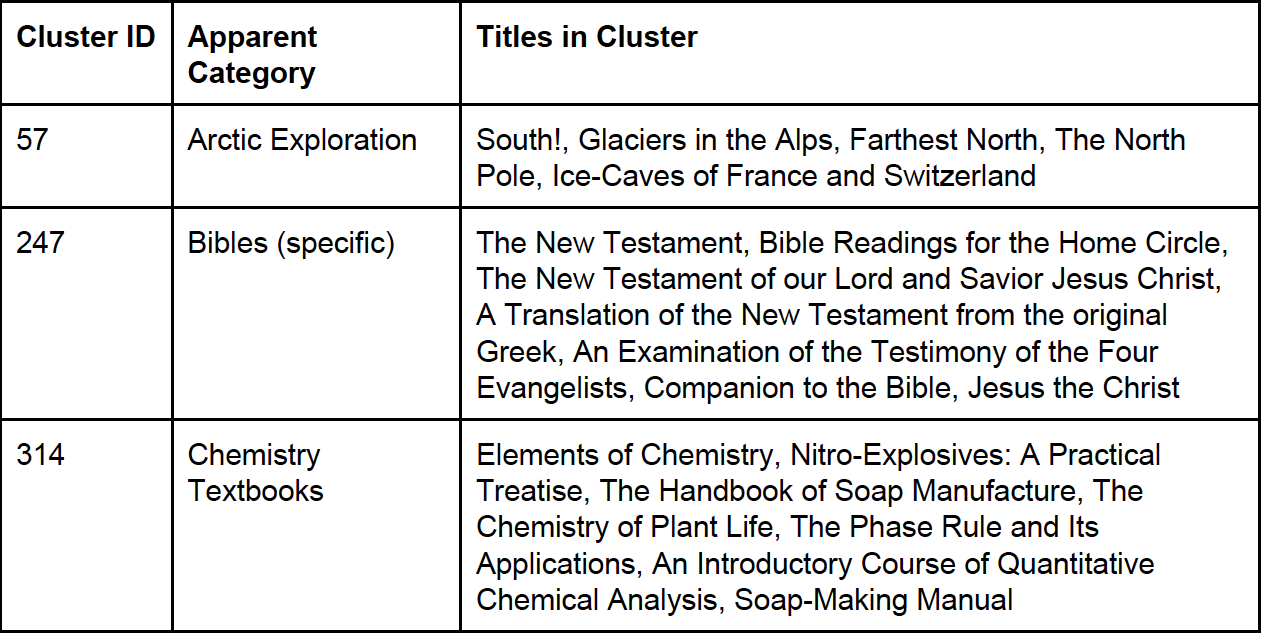
Intermediate-Level Clusters: K = 480
Additional to these features, we also extracted average sentence length and average word length for a basic understanding of the text’s length and the complexity of its vocabulary.
To recap the features extracted thus far, our data now contains each book’s punctuation profile, part-of-speech profile, positive, negative, and neutral sentiment score, author, average sentence length, average word length, and three degrees of content classification. With this in place, we are now ready to implement recommendation algorithms.
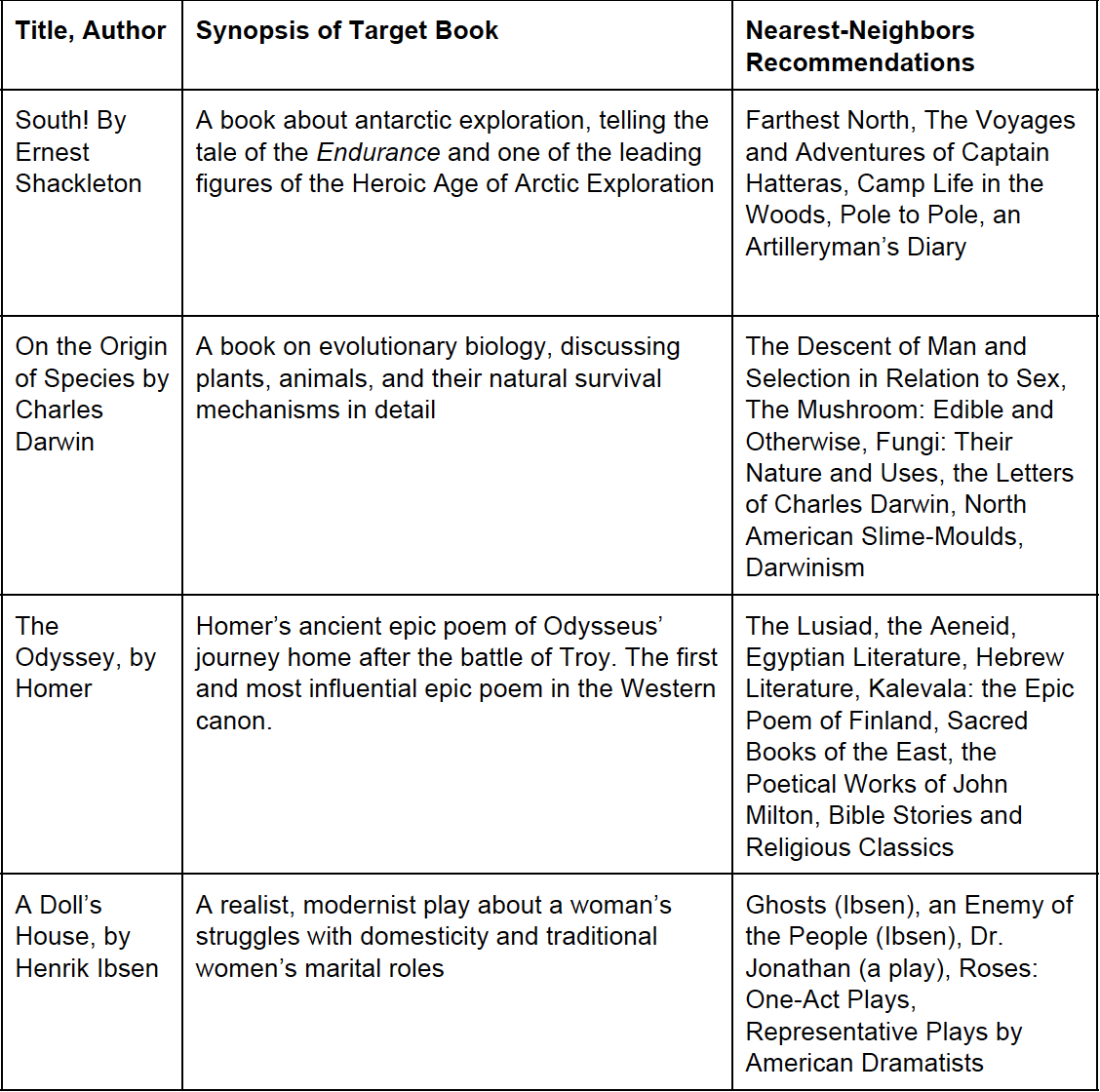
Forming recommendations is quite simple if the data is well-structured. After some experimentation with feature selection, we recommended texts using a k-nearest neighbors algorithm. This is among the most straightforward machine learning algorithms, while simultaneously one of the most reliable and effective for recommendation tasks. Given the input of a book that a user has enjoyed, the algorithm searches through our available book data and finds the ones that are most similar according to the features we have extracted. Using this algorithm, we are able to take one or more books as a baseline for a user’s literary taste profile and recommend any number of similar texts based on the hundreds of features we have extracted from each book.
The final results of our system are shown below. Potential next steps for improving the system include obtaining user ratings data, which would allow for more precise and personalized recommendations, and finding a way to obtain more modern titles for the recommender system, as Project Gutenberg does not contain books that are still controlled by their publishing houses. In the end, the results were encouraging, with the system’s recommendations making strong intuitive sense.
The code for this project can be found on its github repo here.
New project for studying the used and vintage guitar markets
This post explores four algorithms for solving the multi-armed bandit problem (Epsilon Greedy, EXP3, Bayesian UCB, and UCB1), with implementations in Python ...
Multi-armed bandit algorithms are seeing renewed excitement, but evaluating their performance using a historic dataset is challenging. Here’s how I go about ...
An analysis of auction dynamics in client-side header bidding
Using machine learning to predict strategic infield positioning using statcast data and contextual feature engineering.
A quick tutorial on fetching MLB win-loss data with pybaseball and cleaning and visuzlizing it with the tidyverse (dplyr and ggplot).
Tanking becomes a hot topic each season once it becomes apparent which of the NBA’s worst teams will be missing the playoffs. In this post I address the valu...
I’ve been borderline obsessed with the eephus pitch for some time now. Every time I see a player pull this pitch out of their arsenal I become equal parts ex...
For the past three months I have had the exciting opportunity to intern as a data scientist at Major League Baseball Advanced Media, the technology arm of ML...
Throughout my baseball-facing work at MLB Advanced Media, I came to realize that there was no reliable Python tool available for sabermetric research and adv...
A collection of some of my favorite books. Business, popular economics, stats and machine learning, and some literature.
Each cup of coffee I have consumed in the past 5 months has been logged on a spreadsheet. Here’s what I’ve learned by data sciencing my coffee consumption.
Literature is a tricky area for data science. Think of your five favorite books. What do they have in common? Some may share an author or genre, but besides ...
Probabilistic modeling on NFL field goal data. Applying logistic regression, random forests, and neural networks in R to measure contributing factors of fiel...